• 그룹핑시 데이터를 한 노드에서 다른노드로 옮길때
• 성능을 (많이) 저하시킨다

Shuffle을 일으킬 수 있는 작업들
• Join, leftOuterJoin, rightOuterJoin
• GroupByKey
• ReduceByKey
• ComebineByKey
• Distinct
• Intersection
• Repartition
• Coalesce
Shuffle은 이럴때 발생한다
• 결과로 나오는 RDD가 원본 RDD의 다른 요소를 참조하거나
• 다른 RDD를 참조할때
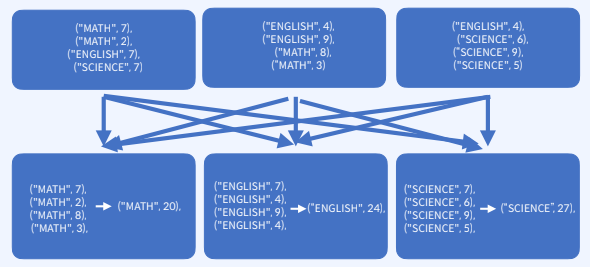

Shuffle을 최소화 하려면
• 미리 파티션을 만들어 두고 캐싱 후 reduceByKey 실행
• 미리 파티션을 만들어 두고 캐싱 후 join 실행
• 둘다 파티션과 캐싱을 조합해서 최대한 로컬 환경에서 연산이 실행되도록 하는 방식
셔플을 최소화 해서 10배의 성능 향상이 가능하다!
Partition은 어떻게 결정될까?
데이터가 어느 노드 / 파티션에
들어가는지는 어떻게 결정될까?
Partition의 특징
• RDD는 쪼개져서 여러 파티션에 저장됨
• 하나의 파티션은 하나의 노드 (서버)에
• 하나의 노드는 여러개의 파티션을 가질 수 있음
• 파티션의 크기와 배치는 자유롭게 설정 가능하며 성능에 큰 영향을 미침
• Key-Value RDD를 사용할때만 의미가 있다
스파크의 파티셔닝 == 일반 프로그래밍에서 자료구조를 선택하는 것
Partition의 종류
Hash Partitioning
데이터를 여러 파티션에 균일하게 분배하는 방식
• [극단적인 예] 2개의 파티션이 있는 상황에서:
- 짝수의 Key만 있는 데이터셋에 Hash 함수가 (x % 2) 라면?
- 한쪽 파티션만 사용하게 될 것
Partition 1: [2, 4, 6, 8, 10, ...]
Partition 2: []
Range Partitioning
순서가 있는, 정렬된 파티셔닝
- 키의 순서에 따라
- 키의 집합의 순서에 따라
서비스의 쿼리 패턴이 날짜 위주면 일별 Range Partition 고려

Memory & Disk Partition
디스크에서 파티션하기
• partitionBy() : 사용자가 지정한 파티션을 가지는 RDD를 생성하는 함수
파티션을 만든 후엔 persist() 하지 않으면:
• 다음 연산에 불릴때마다 반복하게된다! (셔플링이 반복적으로 일어난다)
메모리에서 파티션하기
• repartition()
• coalesce()
Repartition & Coalesce
Repartition과 Coalesce 둘다 파티션의 갯수를 조절하는데 사용
• 둘다 shuffling을 동반하여 매우 비싼 작업
• Repartition: 파티션의 크기를 줄이거나 늘리는데 사용됨
• Coalesce: 파티션의 크기를 줄이는데 사용됨
아래 함수들은 연산중에 새로운 파티션을 만들 수 있다
• Join (leftOuterJoin, rightOuterJoin)
• groupByKey
• reduceByKey
• foldByKey
• partitionBy
• Sort
• mapValues
• flatMapValues
• filter
'데엔(Data-Engineering) > 스파크(Spark)' 카테고리의 다른 글
| [Spark] 04. 스파크 기초(Transformations & Actions / Cache & Persist) (0) | 2023.02.12 |
|---|---|
| [Spark] 03. 스파크 기초 (Distributed Data-Parallel / Key-Value RDD) (0) | 2023.02.12 |
| [Spark] 02. 스파크 기초 (RDD란) (0) | 2023.02.06 |
| [Spark] 01. 스파크 기초 (동작 과정) (0) | 2023.02.06 |




댓글