RDD란
Resilient Distriduted Dataset : 탄력적 분산 데이터셋
왜 RDD를 사용하나?
- 유연하다
- 짧은 코드로 할 수 있는게 많다
- 개발 시 무엇 보다는 어떻게에 대해 더 생각한다.(how-to)
- Lazy execution
#RDD만드는 과정
sc = SparkContext(conf=conf)
lines = sc.textFile(f"file:///{directory}/{filename}")
#위 코드에서는 lines 객체가 RDD
5개 특징
1. 추상화
데이터는 클러스터에 흩어져있지만 하나의 파일인것 처럼 사용 가능하다.
lines = sc.textFile(f"file:///{directory}/{filename}")
#불려온 파일은 여러 노드에 저장되어 있지만, lines 객체를 통해 하나의 파일인것 처럼 사용 가능
2. Resilient & Immutable
탄력적이고 불변하는 성질이 있다.
- 다양한 문제로 부터 자유롭다(노드장애 및 에러,네트워크 장애, 하드웨어&메모리문제, 기타 문제)


Node 1 연산중에 문제 발생 시 이전 기록을 통해 다시 복원 후 Node 2에서 연산하면 된다. => 탄력적
3.Type-safe
- 컴파일 시 Type판별할 수 있어 문제를 빨리 발견할 수 있다.
4.Unstructured / Structured Data
구조화된 데이터 or 비구조화된(law)데이터 둘 다 담을 수 있다.
ex) 로그, 자연어 / RDB, DataFtame
5.Lazy
- 결과가 필요할 때 까지 연산을 진행하지 않는다.
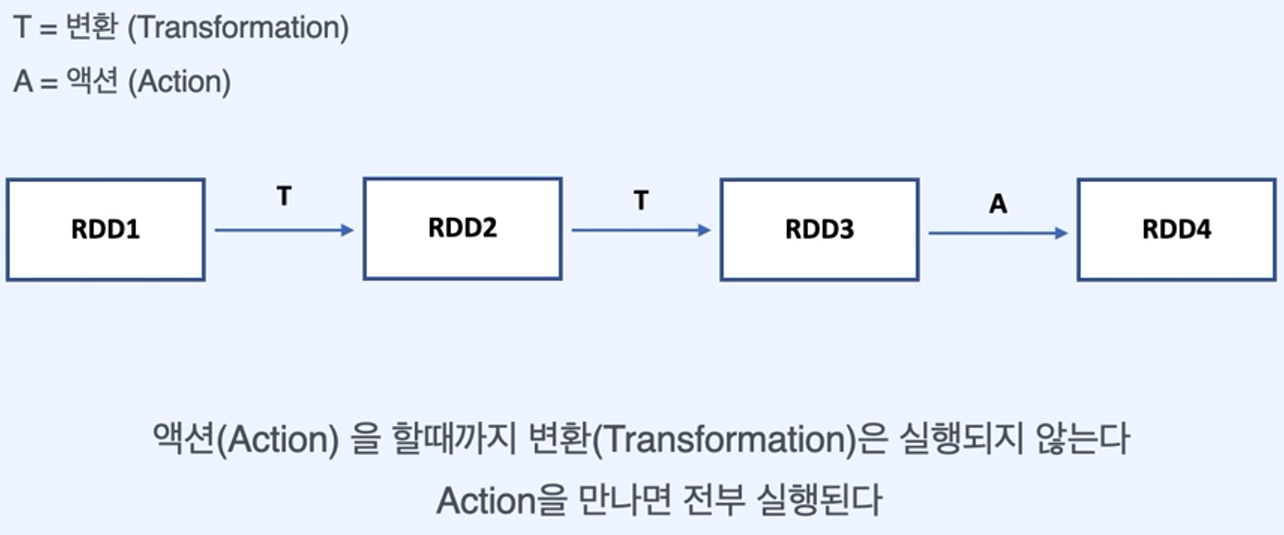
* spark Operation은 두 가지로 나뉜다.
spark Operation = Transform + Action
'데엔(Data-Engineering) > 스파크(Spark)' 카테고리의 다른 글
| [Spark] 05. 스파크 기초(Shuffling & Partitioning) (0) | 2023.02.12 |
|---|---|
| [Spark] 04. 스파크 기초(Transformations & Actions / Cache & Persist) (0) | 2023.02.12 |
| [Spark] 03. 스파크 기초 (Distributed Data-Parallel / Key-Value RDD) (0) | 2023.02.12 |
| [Spark] 01. 스파크 기초 (동작 과정) (0) | 2023.02.06 |




댓글