상황)
원활한 데이터 분석을 위해 ‘시-분-초’ 기준으로 데이터를 분할 저장한다.
- 조회 결과

상황)
원활한 데이터 분석을 위해 ‘시-분-초’ 기준으로 데이터를 분할 저장한다.
- 조회 결과
💡 시-분-초 값을 포함하여 파티션을 나누면 중복 값이 없어서 데이터 수 만큼의 경로(디렉토리)가 만들어질 것으로 예상된다.
- 시 분 초 데이터를 제거 후 연월일 값으로 파티션 테이블 생성해보자
의문점 : 데이터 셋에 중복 데이터는 어떻게 처리될까?
- 2개의 경로? 파일 2개 생성?
2. 개인 실습
💡 시도해 볼 것)
- 연-월-일 기준으로 파티션을 나누어 데이터 저장
- 중복데이터 어떻게 처리되는지 확인
- train데이터 중 1000개의 데이터로 실습을 진행
- 경로nn1 : ~ train1000.csv
실습 진행할 DB 생성
#HIVE CLI
$hive> create database kkwon;
$hive> use kkwon;
테이블 생성(데이터 가져오는 테이블)
#멘토님 코드와 동일
#HIVE CLI
create table test_table (
key date -- STRING타입에서 DATE타입으로 변경
,fare_amount float
,pickup_datetime string
,pickup_longitude int
,pickup_latitude int
,dropoff_longitude int
,dropoff_latitude int
,passenger_count int)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\\n'
STORED AS TEXTFILE
TBLPROPERTIES ('skip.header.line.count'='1');
- 위와 같이 DATABASE와 TABLE 생성하면 HDFS에 경로가 만들어진다
: hdfs://user/hive/warehouse/kkwon.db/test_table
DATA LOAD
#test_table폴더에 train1000.csv파일 복사
#EC2
ubuntu@nn1:~$ hdfs dfs -put train1000.csv /user/hive/warehouse/kkwon.db/test_table/
ec2에서 테이블 폴더에 직접 넣지 않고, hdfs에 저장되어 있는 파일을 가져오는 방법도 있다.
#로컬 또는 EC2에서 HDFS 파일 복사/저장하는 방법
ex) hive> LOAD DATA INPATH '/test_train.csv' INTO TABLE tim.test_table;
※ 단 이 경우 파일 복사(CP)가 아닌 이동(MV)에 해당된다.
결과적으로 테이블의 hdfs 디렉토리 경로에 해당 데이터 파일을 넣어주면 되는 것으로 보인다.
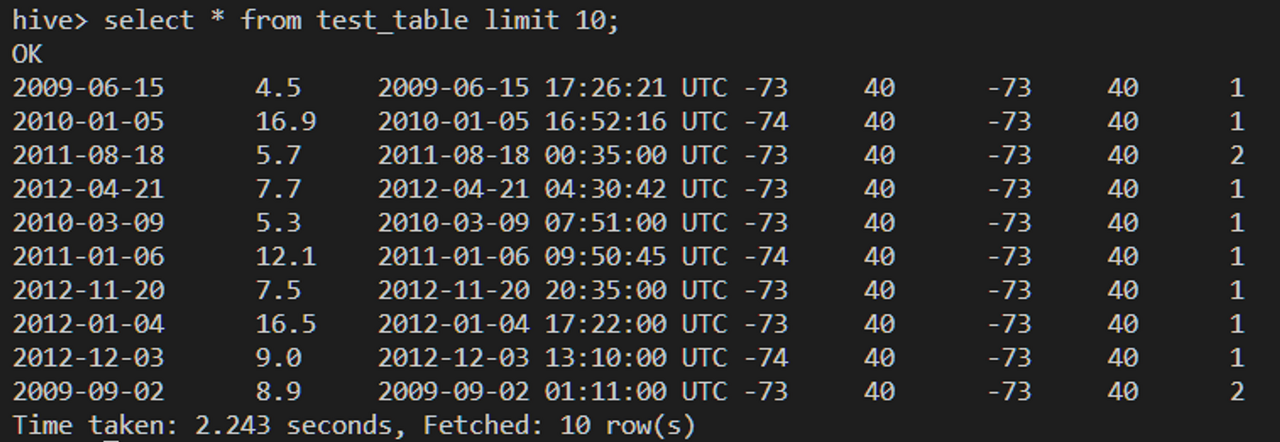
--복사 이후 HIVE에서 테이블 조회하면 테이블 형식에 맞게 train1000.csv데이터가 조회된다.
hive> select * from kkwon.test_table limit 10;
- test_table2생성
: hdfs://user/hive/warehouse/kkwon.db/test_table2
#멘토님 코드와 동일
#HIVE CLI
create table kkwon.test_table2 (
fare_amount float --INT타입에서 FLOAT타입 변경
,pickup_datetime timestamp
,pickup_longitude int
,pickup_latitude int
,dropoff_longitude int
,dropoff_latitude int
,passenger_count int
)
PARTITIONED BY(key date) --변경 전(key timestamp)
-- 이 부분에서 key타입date로 바꾸어주어야 파티션 디렉토리가 연월일로 저장된다.
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\\n'
STORED AS TEXTFILE;
INSERT 데이터 저장
insert overwrite table test_table2 PARTITION(key)
select
fare_amount
,from_unixtime(
unix_timestamp(pickup_datetime
,'yyyy-MM-dd HH:mm:ss'))
,pickup_longitude
,pickup_latitude
,dropoff_longitude
,dropoff_latitude
,passenger_count
,key
from test_table;
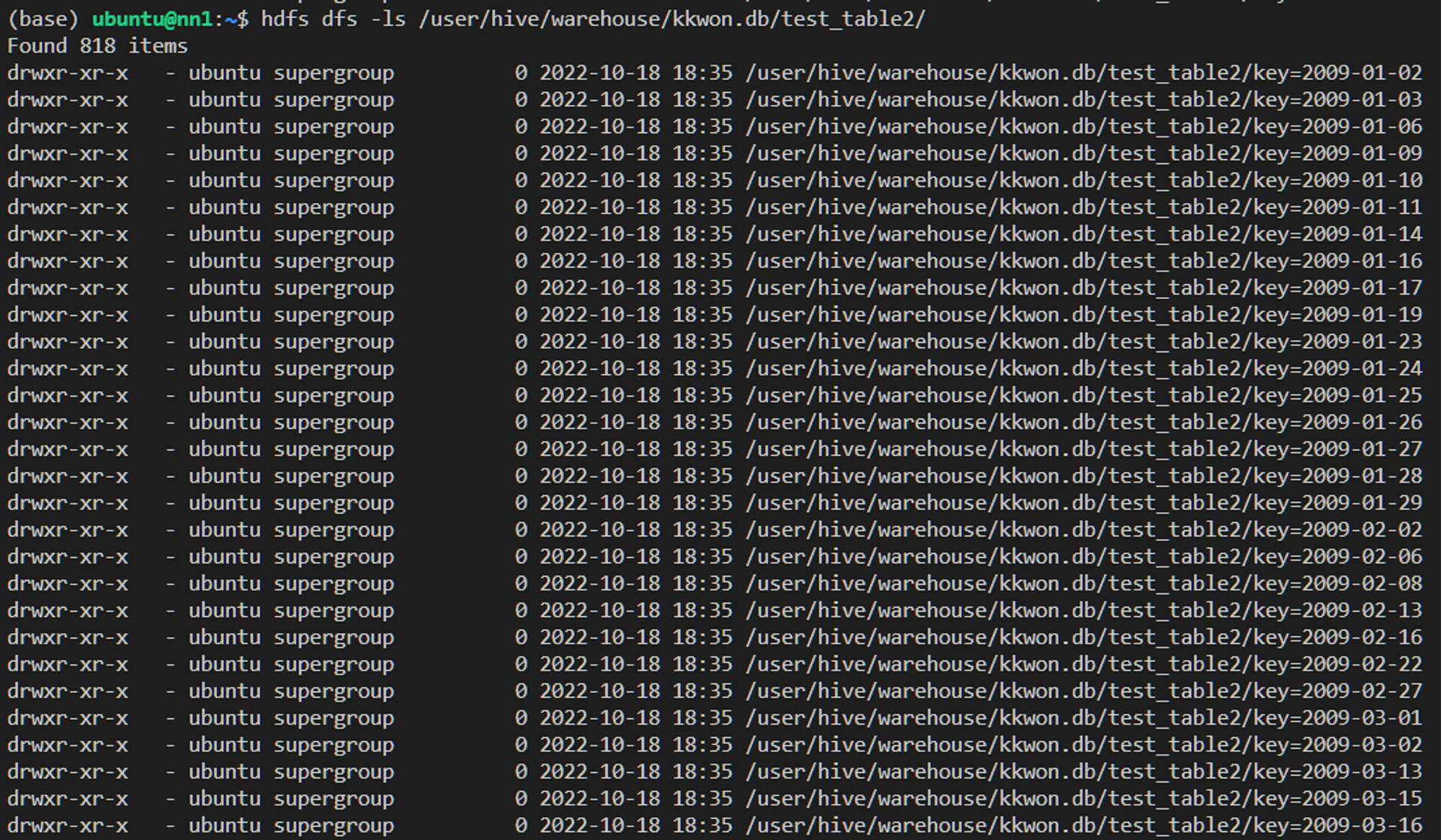
test_table2 조회 결과

hdfs 조회 결과 test_table2 하위 경로로 818개의 경로가 만들어진것을 확인할 수 있다.
182개는 어디로 사라졌는지 확인해보자
중복 확인
hive> SELECT key, COUNT(key) FROM test_table2 GROUP BY key HAVING COUNT(key)>1;
#160개의 날짜가 중복된 것을 확인할 수 있다.

hive> SELECT key, COUNT(key) FROM test_table2 GROUP BY key HAVING COUNT(key)>2; --142개
hive> SELECT key, COUNT(key) FROM test_table2 GROUP BY key HAVING COUNT(key)>3; --14개 * 2
hive> SELECT key, COUNT(key) FROM test_table2 GROUP BY key HAVING COUNT(key)>4; --4개 * 3
**142 + 28 + 12 = 182개 → 부족한 파티션 디렉토리 수와 맞아 떨어진다는 것을 알 수 있다.**
2개 중복 →142개
3개 중복 →14*2개
4개 중복 → 4*3개
hdfs dfs -ls /user/hive/warehouse/kkwon.db/test_table2/key=2010-04-16/
파티션을 통해 데이터 저장할 때, (파티션 기준)중복 데이터가 있을 경우 새로운 경로를 만들거나
파일을 만들지 않고 파일 내부의 데이터에 추가 입력하는 방식으로 중복 데이터 처리하는 것을
확인할 수 있었다.
:파티션별로 만들어진 데이터 → Q. 파일명을 저장하는 기준은 뭘까?
: 이전에 날짜 조회했을 때 2010-04-16 날짜 와 겹치는 데이터는 4개 있었다. → 일치O

#ec2
hdfs dfs -cat /user/hive/warehouse/kkwon.db/test_table2/key=2010-416/000000_0
(결과)
11.3,2010-04-16 17:02:00,-73,40,-73,40,5
14.9,2010-04-16 19:12:00,-73,40,-74,40,2
8.5,2010-04-16 20:35:21,-73,40,-73,40,1
9.7,2010-04-16 21:07:02,-73,40,-73,40,1
#STORED AS TEXTFILE 명령어를 통해 이와 같은 형태로 저장된 것으로 보인다.
3. 정리
- HDFS의 CSV파일을 하이브에서 읽고, 동적 파티션 테이블 생성’ 하려면 2개의 테이블(데이터를 가지고 있는 테이블A 와 A테이블을 통해 동적 파티션 하는 테이블B )과 EC2 or HDFS에 저장된 데이터가 필요하다.
- 데이터가 저장되는 경로는 설정한 파티션을 기준으로 해당 테이블 경로 아래에 “폴더 - 파일” 형태로 저장된다.
'데엔(Data-Engineering) > 하이브(Hive)' 카테고리의 다른 글
| 파티션 (0) | 2022.12.30 |
|---|---|
| 하이브란? (0) | 2022.12.30 |

댓글