1. 프로그래밍 공통
[ OOP란 ]
OOP는 현실 세계를 프로그래밍으로 옮겨와 현실 세계의 사물들을 객체로 보고, 그 객체로부터 개발하고자 하는 특징과 기능을 뽑아와 프로그래밍하는 기법입니다. OOP로 코드를 작성하면 재사용성과 변형가능성을 높일 수 있습니다.
- 캡슐화 : 캡슐화란 하나의 객체에 대해 그 객체가 특정한 목적을 위해 필요한 변수나 메소드를 하나로 묶는 것을 의미
은행이라는 클래스는 잔고라는 변수가 있고 그 잔고를 조회하거나, 잔고를 수정할 수 있는 메서드등이 있다고 치는 것이다.
근데 캡슐화를 하는 중요한 목적은 바로 정보의 은닉화이다. 잔고라는 변수가 만약 public 으로 선언되어있다고 치자. 200만원인 나의 잔고가
누군가 접근에 의해 0원이 될수도 있는 것이다. 따라서 잔고라는 변수를 바로 접근할 수 없도록 private로 선언하고 데이터를 보호하는 것이다.
이렇게 보호된 변수는 getter나 setter등의 메서드를 통해서만 간접적으로 접근이 가능하도록 하는 것이 바로 캡슐화의 중요한 목적이다.
- 추상화: 공통의 속성이나 기능을 묶어 이름을 붙이는 것
클래스를 정의하는 것을 예로 들 수 있다. 다양한 동물들(객체)이 있고, 하나로 묶으려고 할 때 특징을 기준으로 분류하는 것
- 다형성 : 다형성은 상속을 통해 기능을 확장하거나 변경하는 것을 가능하게 해준다. 이를 통해 코드의 재사용, 코드길이 감소가 되어 유지보수가 용이하도록 도와주는 개념이다.
- 상속성:
상속이란 기존 상위클래스에 근거하여 새롭게 클래스와 행위를 정의할 수 있게 도와주는 개념이다.
기존클래스에 기능을 가져와 재사용할 수있으면서도 동시에 새롭게 만든 클래스에 새로운 기능을 추가할 수 있게 만들어 준다.
[ OOP의 5가지 설계 원칙 ]
- SRP(Single Responsibility Principle, 단일 책임 원칙): 클래스는 단 하나의 목적을 가져야 하며, 클래스를 변경하는 이유는 단 하나의 이유여야 한다.
- OCP(Open-Closed Principle, 개방 폐쇠 원칙): 클래스는 확장에는 열려 있고, 변경에는 닫혀 있어야 한다.
- LSP(Liskov Substitution Principle, 리스코프 치환 원칙): 상위 타입의 객체를 하위 타입으로 바꾸어도 프로그램은 일관되게 동작해야 한다.
- ISP(Interface Segregation Principle, 인터페이스 분리 원칙): 클라이언트는 이용하지 않는 메소드에 의존하지 않도록 인터페이스를 분리해야 한다.
- DIP(Dependency Inversion Principle, 의존 역전 법칙): 클라이언트는 추상화(인터페이스)에 의존해야 하며, 구체화(구현된 클래스)에 의존해선 안된다.
[ 절차지향 프로그래밍 VS 객체지향 프로그래밍 ]0
- 절차지향 프로그래밍 : 프로그램의 실행 절차에 중심을 두는 프로그래밍 방법,
- 물이 위에서 아래로 흐르는 것처럼 순차적인 처리를 중요시하는 프로그래밍 기법
- 컴퓨터의 처리구조와 유사해 실행속도가 빠르다.
- 코드의 순서가 바뀌면 동일한 결과를 보장하기 어렵다.
- 대표적인 언어로 C언어
- 전체적인 기능의 동작을 고려한 후 단계별로 기능을 구현
- 컴퓨터의 눈높이와 가까운 언어라 객체지향프로그래밍보다 속도가 빠르지만 유지보수가 어렵고 프로젝트가 커질 시 구조가 복잡해지고 중복 코드 작성 가능성이 있어 개인 프로젝트에 적합
- 객체지향 프로그래밍 OOP : 프로그램에 필요한 객체들의 종류와 속성에 중심을 두는 프로그래밍 방법
- 실제 세계의 사물들을 객체로 모델링하여 개발을 진행하는 프로그래밍 기법
- 캡슐화, 상속, 다형성 등과 같은 기법을 이용할 수 있다. 다형성은 동일한 키보드의 키가 다른 역할을 하는 것처럼 하나의 메소드나 클래스가 다양한 방법으로 동작하는 것을 의미한다.
- 절치지향 언어보다 실행속도가 느리다.
- 대표적으로 많이 알려진 Java언어를 포함하여 Ruby Python, C++, C#, Kotlin 등이 객체지향 요소를 가진 언어이다.
- 객체를 설계 후 각 객체의 상호작용을 설계하는 방식으로 실행
- 절차지향프로그래밍보다 속도가 느린 편이지만 인간 눈높이에서 구조 파악이 쉽고 객체 기능으로 코드를 절약해 생산성 향상에 큰 도움을 주므로 규모가 큰 프로젝트에 적합

[ 인터프리터 VS 컴파일러 ]
고급언어 프로그램의 실행방식의 차이
- 컴파일 언어
- 고급언어로 작성된 코드를 한번에 기계어로 변환하는 프로그램, 전체코드를 한번에 해석하는 것
- 작성한 코드를 컴퓨터가 이해할 수 있는 기계어로 번역한 후에 번역된 코드를 한번에 실행한다.
- 처음 컴파일 시간이 오래 걸린다.
- 한번 컴파일 할 경우, 실행 파일을 실행시킴으로써(컴파일x) 실행 속도가 빠르다.
- C, C++, C#, JAVA
- 인터프리터 언어
- 고급언어로 작성된 코드를 한줄씩 기계어로 변환한다.
- 코드를 한 줄씩 읽으며 바로바로 실행하는 프로그램을 말한다.
- 컴파일 과정이 없기 때문에 코드 수정이나 추가가 잦을 경우 빠른 동작이 가능
- 실행파일을 별도로 생성하지 않기 때문에 매번 새롭게 전체 과정을 반복 수행한다는 특징이 있다.(반복 수행 시 비효율적)
- python, javascript, R, Ruby, PHP
| 컴파일러 언어 | 인터프리터 언어 |
| 코드 실행 전, 컴파일 타임에 소스 코드 전체를 한번에 기계어로 변환 후 실행 | 코드가 실행 단계인 런타임에 코드 한 줄씩 중간 코드인 바이트코드로 변환 후 실행 |
| 실행 파일 생성 | 실행 파일 생성 X |
| 컴파일 단계와 실행 단계가 분리 | 인터프리트 단계와 실행 단계 분리 X 인터프리터는 한 줄씩 바이트코드로 변환 후 즉시 실행 |
| 컴파일은 한번만 수행 | 코드 실행시마다 인터프리트 과정 반복 수행 |
| 컴파일과 실행단계가 분리되어 있어, 실행시에는 실행만 하면 되므로 코드 실행 속도 빠름 | 인터프리트 단계와 실행 단계가 분리되어 있지 않아 반복 수행하므로 실행 속도가 느림 |
*자바는 하이브리드 언어라고도 불린다.
컴파일러가 전체 코드 변역하고, 이후 JVM이 실행시킬 수 있는 자바 바이트 코드로 번역한다.
자바 바이트 코드로 작성되어 있는 실행 프로그램을 자바 인터프리터가 한 줄씩 읽으면서 컴퓨터가 이해할 수 있는 2진 코드로 번역한 후 실행시킨다.
=> 컴파일, 자바바이트코드 변환까지의 과정은 컴파일 언어의 특징을 보이지만, 이후 자바 인터프리터가 한 줄씩 읽으며 2진 코드로 번역 후 실행 시키는 과정은 인터프리터언어의 특징을 보인다. 그래서 하이브리드 언어라도 함
[ RESTful API ]
REST(REpresentational State Transfer)ful API는 HTTP 통신에서 어떤 자원에 대한 CRUD 요청을 Resource와 Method로 표현하여 특정한 형태로 전달하는 방식입니다. RESTful API는 아래와 같은 것들로 구성됩니다.
- Resource(자원, URI)
- Method(요청 방식, GET or POST 등)
- Representation of Resource(자원의 형태, JSON or XML 등)
[ 함수형 프로그래밍 ]
함수평 프로그래밍의 가장 큰 특징은 immutable data와 first class citizen으로서의 함수입니다. 함수형 프로그래밍은 부수효과가 없는 순수 함수를 이용하여 프로그램을 만드는 것이다. 부수 효과가 없는 순수 함수란 데이터의 값을 변경시키지 않으며 객체의 필드를 설정하는 등의 작업을 하지 않는 함수를 의미합니다.
[ 메모리 구조 ]
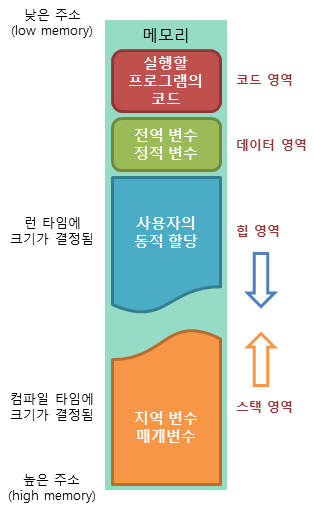
- 코드 영역: 실행할 프로그램의 코드가 저장되는 영역으로 텍스트 영역이라고도 부릅니다. 사용자가 프로그램 실행 명령을 내리면 OS가 HDD에서 메모리로 실행 코드를 올리게 되고, CPU는 코드 영역에 저장된 명령어를 하나씩 처리하게 됩니다.
- 데이터 영역: 프로그램의 전역 변수(global)와 정적 변수(static)가 저장되는 영역입니다. 데이터 영역은 프로그램의 시작과 함께 할당되며, 프로그램이 종료되면 소멸합니다.
- 힙 영역: 프로그래머가 직접 관리할 수 있는 메모리 영역으로 이 공간에 메모리를 할당하는 것을 동적 할당이라고 부릅니다. Java에서는 가비지 컬렉터가 자동으로 해제해줍니다. 힙 영역은 스택 영역과 달리 낮은 주소에서 높은 주소로 메모리가 할당됩니다.
- 스택 영역: 함수의 호출과 함께 할당되며 지역 변수와 매개 변수가 저장되는 영역입니다. 스택 영역에 저장되는 함수의 호출 정보를 스택프레임이라고 합니다. 스택 영역은 함수의 호출이 완료되면 소멸합니다. 스택 영역은 높은 주소에서 낮은 주소로 메모리가 할당됩니다.
[ Parameter와 Argument의 차이 ] 0
- Parameter, 매개변수 : 함수를 선언할 때 사용된 변수
def plus(str1, str2):
return str1 + str1
#plus 함수 정의에서 str1과 str2는 parameter 입니다.
plus("parameter", "argument")
#plus 함수를 호출할 때, 입력값 “parameter”와 “argument”는 argument입니다.- Argument, 인수, 전달인자 : 함수가 호출되었을 때 함수의 파라미터로 전달된 실제 값
[ Call By Value와 Call By Reference 차이 ]
- Call By Value
- 인자로 받은 값을 복사하여 처리하는 방식
- Call By Value에 의해 넘어온 값을 증가시켜도 원래의 값이 보존된다.
- 값을 복사하여 넘기기 때문에 메모리 사용량이 늘어난다.
- Call By Reference
- 인자로 받은 값의 주소를 참조하여 직접 값에 영향을 주는 방식
- 값을 복사하지 않고 직접 참조하기 때문에 속도가 빠르다.
- 원래의 값에 영향을 주는 리스크가 존재한다.
예를 들어 아래와 같은 코드가 있다고 할 때, a라는 새로운 변수가 생성되어 Call By Value로 전달되기 때문에 메모리를 많이 사용하지만 a를 변경하여도 원래 값인 f는 영향을 받지 않습니다.
public class Main {
public static void main(String[] args) {
Foo f = new Foo("f");
changeReference(f); // It won't change the reference!
modifyReference(f); // It will modify the object that the reference variable "f" refers to!
}
public static void changeReference(Foo a) {
Foo b = new Foo("b");
a = b;
}
public static void modifyReference(Foo c) {
c.setAttribute("c");
}
}
[ 프레임워크와 라이브러리 차이 ] 0
- 라이브러리: 사용자가 흐름에 대한 제어를 하며 필요한 상황에 가져다가 쓸 수 있다.
- 프레임워크: 전체적인 흐름을 자체적으로 제어한다.
프레임워크와 라이브러리는 실행 흐름에 대한 제어 권한이 어디 있는지에 따라 달라집니다.
라이브러리의 경우 사용자가 흐름에 대한 제어를 하며 원하는 기능을 상황에 따라 가져다 사용할 수 있다.
프레임워크를 사용하면 사용자가 관리해야 하는 부분을 프레임워크가 대신함으로서 신경써야 할 것을 줄이는 제어의 역전(IoC, Inversion Of Control)이 적용됩니다.
[ 병렬 처리 프레임워크의 종류와 특징 ]
- Hadoop
- HDFS(Hadoop Distributed File System)를 활용해 데이터를 주고 받는다.
- 데이터가 여러 노드에 분산되어 저장되기 때문에 손실의 우려가 없다는 장점이 있다.
- 하지만 File I/O를 기반으로 작동하기 때문에 처리 속도가 느리다.
- Spark
- In-Memory 상 에서 데이터를 주고받고 연산을 수행한다.
- 메모리를 사용해 데이터를 처리하기 때문에 Hadoop보다 속도가 약 100배 정도 빠르다.
- 하지만 메모리상에서 처리하기 때문에 장애가 발생한 경우 응용 프로그램을 처음부터 다시 시작해야 한다.
[ 동기와 비동기의 차이 ]
- 동기(Synchronous) 방식
- 요청을 보내고 실행이 끝나면 다음 동작을 처리하는 방식
- 순서에 맞추어 진행되기 때문에 제어하기 쉽다.
- 여러가지 요청을 동시에 처리할 수 없어 효율이 떨어진다.
- 동기 방식의 예시로는 콜센터 종업원이 일을 처리하는 방식이 될 수 있다. 콜센터의 직원은 한 손님의 전화 응대가 끝난 후에 다음 손님의 응대를 진행할 수 있다.
- 비동기(Asynchronous) 방식
- 요청을 보내고 해당 동작의 처리 여부와 상관없이 다음 요청이 동작하는 방식
- 작업이 완료되는 시간을 기다릴 필요가 없기 때문에 자원을 효율적으로 사용할 수 있다.
- 작업이 완료된 결과를 제어하기 어렵다.
- 비동기 방식의 예제로는 이메일이 있다. 우리는 한 사람에게 이메일을 보냈을 때 답변을 받지 않고도 이메일을 다시 보낼 수 있다.
[ SQL Injection ] 0
SQL Injection이란 공격자가 악의적인 의도를 갖는 구문을 삽입하여 공격자가 원하는 SQL을 실행하도록 하는 웹해킹기법입니다. 예를 들어 아래와 같은 간단한 SQL 문이 있을 때 INPUT1에 'OR 1=1--을 넣는 것입니다.
SELECT * FROM USER WHERE ID = 'INPUT1' AND PASSWORD = 'INPUT2'
SELECT * FROM USER WHERE ID = '' OR 1=1 --INPUT1' AND PASSWORD = 'INPUT2'INPUT1으로 'OR 1=1--을 넣으면 보이는 것처럼 뒤의 내용은 주석처리가 되고 WHERE 문은 항상 참이 됩니다.
이러한 공격을 방지하기 위해 특수문자 및 SQL 예약어들을 필터링하거나 SQL 오류 메세지를 노출하지 않는 등의 방법을 취해야 합니다.
1. 프로그래밍 공통 - 고급
[ 메세지 큐(Message Queue)란? ]
메세지 큐(Message Queue)란 Queue 자료구조를 이용하여 데이터(메세지)를 관리하는 시스템으로, 비동기 통신 프로토콜을 제공하여 메세지를 빠르게 주고 받을 수 있게 해준다. 메세지 큐에서는 Producer(생산자)가 Message를 Queue에 넣어두면, Consumer가 Message를 가져와 처리하게 된다. 메세지 큐에는 Kafka, Rabbit MQ, AMPQ 등이 있다.
[ Docker(도커)와 Kubernates(쿠버네티스) ]
Docker는 컨테이너 기반의 가상화 기술입니다. 기존에는 하드웨어를 가상화하였기 때문에 Host OS 위에 Guest OS를 설치해야 했습니다. 하지만 이러한 방식은 상당히 무겁고 느려 한계가 많이 있었습니다.
그래서 이를 극복하고자 프로세스를 격리시킨 컨테이너를 통해 가상화를 하는 Docker(도커)와 같은 기술들이 등장하게 되었고, 도커를 통해 구동되는 컨테이너를 관리하기 위한 Kubernates(쿠버네티스)가 등장하게 되었습니다.
[ Docker(도커)의 장/단점 ]
- 장점
- 쉽고 빠른 실행 환경 구축
- 하드웨어 자원 절감
- Docker Hub와 같은 공유 환경 제공
- 단점
- 개발 초기의 오버헤드
- Linux 친화적
[ TDD(Test-Driven Development) ]
TDD(Test-Driven Development)는 매우 짧은 개발 사이클의 반복에 의존하는 개발 프로세스로, 개발자는 우선 요구되는 기능에 대한 테스트케이스를 작성하고, 그에 맞는 코드를 작성하여 테스트를 통과한 후에 상황에 맞게 리팩토링하는 테스트 주도 개발 방식을 의미합니다.
개발자는 테스트를 작성하기 위해 해당 기능의 요구사항을 확실히 이해해야 하기 때문에 개발 전에 요구사항에 집중할 수 있도록 도와주지만 테스트를 위한 진입 장벽과 작성해야 하는 코드의 증가는 단점으로 뽑힙니다.
[ DDD(Domain-Driven Design) ]
DDD(Domain-Driven Design)는 실세계에서 사건이 발생하는 집합인 Domain(도메인)을 중심으로 설계하는 방법입니다. 옷 쇼핑몰을 예로 들면 손님들이 주문하는 도메인, 점주들이 관리하는 도메인 등이 있을 수 있습니다. 이러한 도메인들이 서로 상호작용하며 설계하는 것이 도메인 주도 설계입니다. 도메인 주도 설계에서 도메인은 각각 분리되어 있는데, 이러한 관점에서 MSA(MicroService Architecture)를 적용하면 용이한 설계를 할 수 있다. DDD에서는 같은 객체들이 존재할 수 있는데, 예를 들어 옷 구매자의 입장에서는 (name, price)와 같은 객체 정보를 담지만, 판매자의 입장에서는(madeTie, size, madeCountry) 등이 있을 수 있습니다. 즉, 문맥에 따라 객체의 역할이 바뀔 수 있는 것이 DDD입니다.

[ MSA란? ]
MSA(Microservice Architecture)는 모든 시스템의 구성요소가 한 프로젝트에 통합되어 있는 Monolithic Architecture(모놀리식 아키텍쳐)의 한계점을 극복하고자 등장하게 되었습니다. MSA는 1개의 시스템을 독립접으로 배포가능한 각각의 서비스로 분할합니다. 각각의 서비스는 API를 통해 데이터를 주고받으며 1개의 큰 서비스를 구성합니다.

- 장점
- 일부 서비스에 장애가 발생하여도 전체 서비스에 장애가 발생하지 않는다.
- 각각의 서비스들은 서로 다른 언어와 프레임워크로 구성될 수 있다.
- 서비스의 확장이 용이하다.
- 단점
- 서비스가 분리되어 있어, 테스팅이나 트랜잭션 처리 등이 어렵다.
- 서비스 간에 API로 통신하기 때문에 그에 대한 비용이 발생한다.
- 서비스 간의 호출이 연속적이기 때문에 디버깅 및 에러 트레이싱이 어렵다.
'CS' 카테고리의 다른 글
| 3. 알고리즘 (0) | 2023.01.30 |
|---|---|
| 2. 자료구조 (0) | 2023.01.30 |
| 3 -Tier - Architecture (0) | 2023.01.20 |
| 컴파일러(compiler), 인터프리터(interpreter) 차이 (0) | 2022.12.29 |
| Hardware, Middleware, Software 차이 (0) | 2022.12.15 |



댓글